Building and Deploying Your First Cloud Application on IBM Cloud from a non-Developer Point-of-View
Every now and then I have an idea and I try to explore it as far as I can. This time, I wanted to create a Slack Bot, using Python and Flask, and a Cloudant database. The purpose of the application was to save and query data to/from the database, and everything being hosted in IBM Cloud (the internals of the application do not matter much for this writeup though).
For this Proof-of-Concept (PoC) or pet project, the plan was also to learn k8s along the way, and decided to go with the IBM Cloud Kubernetes Service, or IKS — the “hardcore way”.
Note that in a production environment, you want to use Gunicorn as your WSGI HTTP Server instead of Werkzeug (wrapped into Flask), the latter being more suited for development environements.
Considerations — or — What do we need?
Starting from scratch, I needed to build my application (obviously), stand up a Cloudant database, build my pipeline, a handful of scripts, a {Docker,Container}file, and get a me (free and classic) cluster on IBM Cloud.
Is that it, you’ll ask? Yes. Well. No. Surprises come when you expect them the less. Be patient.
Note that I will not go into the details and steps to create yourself an account on IBM Cloud. See this link for how to do it.
The Architecture
Basic architecture diagram kept, on purpose, very abstract.

The IBM Cloud Environment
Note that since we’re using the (30 days) free cluster option on IBM Cloud, there are some caveats. An important one to note is what options are available to us to expose our application to the outside and make it available to Internet access by using the public IP address of any worker node in our Kubernetes cluster. Unfortunately, only the use of NodePort is available.
In order to prepare for our CI/CD pipeline and related scripts, get these environment variables ready:
IBM_CLOUD_API_KEY: your IBM Cloud API keyIBM_CLOUD_REGION: the region where you cluster is deployed (i.e. us-south or eu-de)IBM_CLOUD_RESOURCE_GROUP: Your first resource group is created and namedDefaultfor you. You can update the name of this group or any other groups that you create.ICR_NAMESPACE: your IBM Cloud Registry namespaceIKS_CLUSTER: obviously… your cluster name
Note: in case you have no IBM Cloud Registry namespace yet, here’s a link to the quick start guide: https://cloud.ibm.com/registry/start
The Database
Let’s start with the easiest one. Create your service instance, and save the following information as environment variables that we will use later on: CLOUDANT_API_KEY, CLOUDANT_DB, and CLOUDANT_URL.
The Bot
Prerequisites: ensure you do have access to a Slack environment where you can install and deploy your application into workspaces.
First of all you want to create your Slack App and a Bot User. In my application, I wanted the bot to respond to Slash Commands only, but you can do whatever you need with the bot. It’s not the purpose of this article.
Once done, save your Signing Secret, in the Basic Information > App Home > App Credentials section (to be used later on as SLACK_SIGNING_SECRET environment variable), and your Bot User OAuth Token, in the Features > OAuth & Permissions section (to be used later on as SLACK_BOT_TOKEN environment variable), as we’ll need them later. Add your Scopes too in the Features > OAuth & Permissions > Scopes section.
The Scripts and the Pipeline
Assuming you already have your code repository setup (I’m using GitHub), connect it to your favorite Continuous Integration software (I’m using TravisCI). In Travis, I define my environment variables in the repository settings. Take the ones we have mentioned above, and add them. We’ll add more of them later on.
Let’s start with our Containerfile. Nothing fancy or out of the ordinary.
# Base Image
FROM registry.access.redhat.com/ubi8 AS compile-imageENV HOME="/opt/app-root/src" \
PORT=5000 \
PATH=$HOME/bin:$PATH# Install packages
USER 0
RUN dnf install -y python39-pip python39-wheel python39-setuptools\
&& pip3 install -v --upgrade pip# Add application and drop permissions
COPY . ${HOME}
WORKDIR ${HOME}
RUN chown -R 1001:0 ${HOME}
USER 1001# Install Requirements
RUN pip3 install --user -v -r requirements.txt
RUN pip3 install --user -v .# Exposing the port
EXPOSE ${PORT}ENTRYPOINT [ "python3" ]
CMD [ "path/to/your/app.py" ]
Next up is our very simple, yet straight-forward, .travis.yml file:
language: pythonpython:
- "3.9"services:
- dockerscript:
- make ibm-cloud
As you can see, we’re calling a make(1) target, specifically written for our IBM Cloud environment. So, let’s have a quick look at our very simple Makefile.
Podman or Docker? Let’s figure it out and act as accordingly.
CONTAINER_ENGINE := $(shell command -v podman 2> /dev/null || echo docker)ifeq ($(CONTAINER_ENGINE),docker)
BUILDFLAGS +=
else
BUILDFLAGS += --format docker
endif
Next, let’s get our environment variables from Travis CI.
CLUSTER := $(IKS_CLUSTER)
DEPLOYMENT_NAME := $(DEPLOYMENT_NAME)
IBM_CLOUD_API_KEY := $(IBM_CLOUD_API_KEY)
IBM_CLOUD_REGION := $(IBM_CLOUD_REGION)
IBM_CLOUD_RESOURCE_GROUP := $(IBM_CLOUD_RESOURCE_GROUP)
ICR_NAMESPACE := $(ICR_NAMESPACE)
REGISTRY := $(REGISTRY_HOSTNAME)
IMAGE := $(IMAGE_NAME)
IMAGE_REF := $(REGISTRY)/$(ICR_NAMESPACE)/$(IMAGE)
PORT := $(PORT)
# Git commit hash
HASH := $(shell git rev-parse --short HEAD).EXPORT_ALL_VARIABLES: ; # Send all variables to shell
Notice that there are environment variables that we haven’t set yet, such as DEPLOYMENT_NAME, and IMAGE_NAME. Set those to your likings and add them to TravisCI like the previous ones.
The last line is golden. This allows us to get the above environment variables in our shell, which will come handy when we call our shellscript to deploy the application to our IBM Cloud environment.
And now our targets:
.PHONY: all
all: build.PHONY: build image_build image_tag
build: image_build image_tagimage_build:
$(CONTAINER_ENGINE) build $(BUILDFLAGS) -f Containerfile -t $(IMAGE_REF):$(HASH) .image_tag:
$(CONTAINER_ENGINE) tag $(IMAGE_REF):$(HASH) $(IMAGE_REF):latestibm_cloud: build
/bin/bash ./scripts/ibm-cloud.sh
Notice the last couple lines, calling our ibm-cloud.sh shellscript. Let’s dive into that one.
#!/bin/bashset -ex# Install the IBM Cloud CLI and plug-ins
curl -sL https://ibm.biz/idt-installer | bash
ibmcloud --version
ibmcloud config --check-version=false
ibmcloud plugin install -f kubernetes-service
ibmcloud plugin install -f container-registry# Log into our environment
ibmcloud login --apikey "${IBM_CLOUD_API_KEY}" -r "${IBM_CLOUD_REGION}" -g "${IBM_CLOUD_RESOURCE_GROUP}"
ibmcloud cr region-set "${IBM_CLOUD_REGION}"# Log into the registry
"${CONTAINER_ENGINE}" login -u iamapikey -p "${IBM_CLOUD_API_KEY}" "${REGISTRY}"# Push image to registry
"${CONTAINER_ENGINE}" push "${IMAGE_REF}":"${HASH}"
"${CONTAINER_ENGINE}" push "${IMAGE_REF}":latest# List the tagged images in IBM Cloud Container Registry
ibmcloud cr image-list# Deploy
# Ensure we're working in the right cluster context
ibmcloud ks cluster config --cluster "${CLUSTER}"
kubectl config current-context# Get the latest and greatest image ref. and
# ... apply our configuration
sed "s|{{YOUR_IMAGE}}|${IMAGE_REF}:${HASH}|" "./deployment.yaml" | kubectl apply -f -# Not the prettiest, but delete service because for some reason it does not replace it...
kubectl delete service "${DEPLOYMENT_NAME}"# NodePort, only option on for the free cluster we're testing on
kubectl expose deployment/"${DEPLOYMENT_NAME}" --type=NodePort --port="${PORT}"kubectl rollout status deployment/"${DEPLOYMENT_NAME}"
You must have noticed that in the above we have called and used a deployment.yaml, a Kubernetes YAML file, also called a manifest. As you may know, these YAML files describe all the components and configurations of your Kubernetes app, and can be used to easily create and destroy your app in any Kubernetes environment. Here, for our purpose, we are using the simplest version possible.
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: <your app here>
name: <your app here>
spec:
replicas: 1
selector:
matchLabels:
app: <your app here>
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: <your app here>
spec:
containers:
# Keep the {{ }} as they are needed for the deployment script
- image: {{<YOUR_IMAGE>}}
name: <your app here>
resources: {}
env:
- name: CLOUDANT_APIKEY
valueFrom:
secretKeyRef:
name: cloudant-apikey
key: CLOUDANT_APIKEY
- name: CLOUDANT_DB
valueFrom:
secretKeyRef:
name: cloudant-db
key: CLOUDANT_DB
- name: CLOUDANT_URL
valueFrom:
secretKeyRef:
name: cloudant-url
key: CLOUDANT_URL
- name: SLACK_BOT_TOKEN
valueFrom:
secretKeyRef:
name: slackbot-token
key: SLACK_BOT_TOKEN
- name: SLACK_SIGNING_SECRET
valueFrom:
secretKeyRef:
name: slack-signing-secret
key: SLACK_SIGNING_SECRET
status: {}We are using this one to expose our environment variables (or secrets) holding our Cloudant database credentials, and Slack tokens, that we discussed earlier in this article.
First, let’s get these secrets created.
$ kubectl create secret generic cloudant-api-key \
--from-literal=CLOUDANT_API_KEY=<your api key>$ kubectl create secret generic cloudant-db \
--from-literal=CLOUDANT_DB=<your database name>$ kubectl create secret generic cloudant-url \
--from-literal=CLOUDANT_URL=<your cloudant url>$ kubectl create secret generic slack-signing-secret \
--from-literal=SLACK_SIGNING_SECRET=<your slack signing secret>$ kubectl create secret generic slackbot-token \
--from-literal=SLACK_BOT_TOKEN=<your slackbot token>
… and verify they are there:
$ kubectl get secrets
NAME TYPE DATA AGE
[...]
cloudant-apikey Opaque 1 11d
cloudant-db Opaque 1 11d
cloudant-url Opaque 1 11d
[...]
slack-signing-secret Opaque 1 11d
slackbot-token Opaque 1 11dOnce we have reached this point, every commit to your GitHub repository will trigger a TravisCI build, and a deployment to your IBM Cloud environment.
Using the IBM Cloud Shell, you can now verify that everything is running properly, and get your NodePort value that we will need later one for the Slash Commands and Event Subscriptions setup.
<user>@cloudshell:~$ ibmcloud ks cluster config --cluster <your cluster>
OK
The configuration for <your cluster> was downloaded successfully.Added context for <your cluster> to the current kubeconfig file.
You can now execute 'kubectl' commands against your cluster. For example, run 'kubectl get nodes'.
If you are accessing the cluster for the first time, 'kubectl' commands might fail for a few seconds while RBAC synchronizes.<user>@cloudshell:~$ kubectl get pods
NAME READY STATUS RESTARTS AGE
<your pod name> 1/1 Running 0 3h29m<user>@cloudshell:~$ kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
<service> NodePort 172.21.154.196 <none> 5000:31889/TCP 3h29m app=<your app name>
Here, our NodePort value will be 31889.
Note that if your pod is not in a Running status but rather CrashLoopBackOff, start with the following command to view your application logs:
<user>@cloudshell:~$ kubectl logs <your pod name>The Code
I will not specifically cover the aspect on how to code or develop a Slack Bot per say, as there are already many articles our there covering this topic. That being said, I will highlight couple of areas that are important to get your Slack Bot running. Note that for this proof-of-concept, we have decided to use the Slack Events API adapter for Python, a solution to receive and parse events from Slack’s Events API.
For this project, I’m using a config.py configuration module where I get and set my environment variables:
#!/usr/bin/env python
# -*- coding=utf8 -*-
"""Configuration Module."""
import osSLACK_BOT_TOKEN = os.getenv("SLACK_BOT_TOKEN", "")
SLACK_SIGNING_SECRET = os.getenv("SLACK_SIGNING_SECRET", "")
CLOUDANT_DB = os.getenv("CLOUDANT_DB", "")
… variables that are used in my app.py application main file:
#!/usr/bin/env python
# -*- coding=utf8 -*-
"""Flask App Module."""
from config import SLACK_BOT_TOKEN, SLACK_SIGNING_SECRET[...]from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from slackeventsapi import SlackEventAdapterapp = Flask(__name__)slack_events_adapter = SlackEventAdapter(SLACK_SIGNING_SECRET, "/slack/events", app)
slack_web_client = WebClient(token=SLACK_BOT_TOKEN)[...]
… and db.py module for all database related functions:
#!/usr/bin/env python
# -*- coding=utf8 -*-
"""Database Functions Module."""
import loggingfrom config import CLOUDANT_DBfrom ibmcloudant.cloudant_v1 import AllDocsQuery, CloudantV1, Document
from ibm_cloud_sdk_core import ApiExceptionlogger = logging.getLogger(__name__)service = CloudantV1.new_instance()
Note that here I’m using IBM Cloudant Python SDK.
The Slack Bot Configuration
Now with all of the above, we’re in a good place to start configuring our Slack Bot Slash Commands and Events Subscriptions. For this we will require the worker node’s public IP as well as the NodePort value (scroll up, its 31889). To get your worker node’s IP address, you can either use the command-line inteface (CLI) in the IBM Cloud Shell using the following command:
$ ibmcloud ks workers --cluster <cluster name>
… or on your cluster’s page, via the user-interface with your browser:

With that, go to your Slack App user-interface and go to the Features > Slash Commands section. In the Create New Command dialog, for the Request URL value, use the above public IP address and the NodePort in the following format: https://<ip>:<NodePort>/your/command/endpoint. Repeat this step as many times as you need for all your commands.
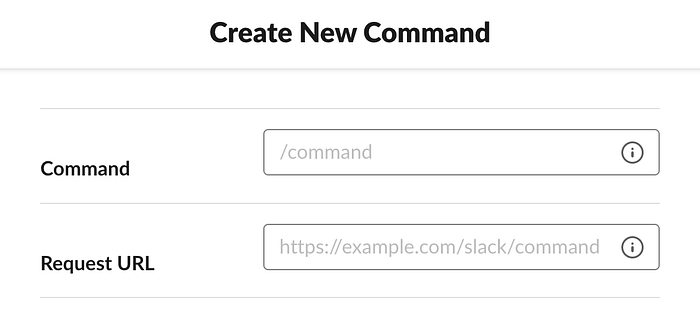
Once you’re done, it’s time to enable the Event Subscriptions (go to Features > Event Subscriptions section), and use again your public IP address, the NodePort, and the Slack Event Adapter for receiving actions via the Events API (“/slack/events”).
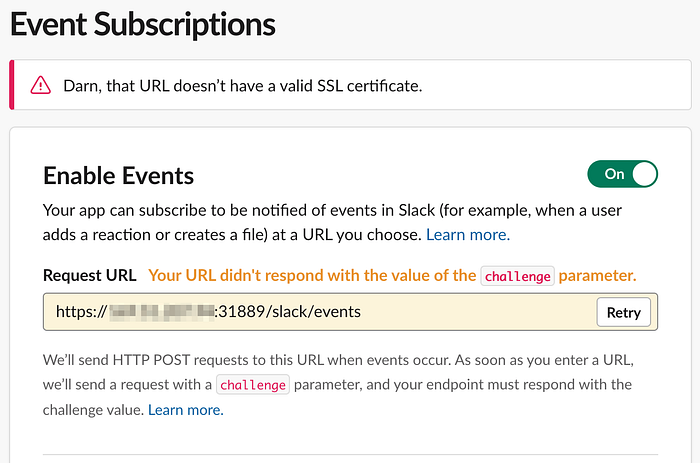
Ooops. SSL certificate error message. As we’re in a development environment and working on a proof-of-concept, we have enabled Flask to run with a self-signed (or Adhoc) SSL certificate, unfortunately Slack does not accept it.
You could try your Slash Commands, but you will likely get similar error as below:

As stipulated in their FAQ, SSL certificates must be signed by a reputable certificate authority, and they suggest to consider using one of the following low-cost providers:
To determine whether your certificate is valid, consider using this tool provided by SSL Labs.
OK, so what’s next you’ll ask.
The SSL Nightmare^WCertificate
After releasing all my frustration (thank you Criveti Mihai), I have decided to go with with Let’s Encrypt, using the acme-account-creation-tool, an utility to create or retrieve an account with certificate authorities that support the Automatic Certificate Management Environment (ACME) protocol, which supports Let’s Encrypt out of the box.
One thing leading to another, you start thinking about where you’re going to store that now “production-like” certificate… IBM Cloud Secret Manager. Luckily there is a (30 days) Trial plan that we can use.
With Secrets Manager, you can create, lease, and centrally manage secrets that are used in IBM Cloud services or your custom-built applications. Secrets are stored in a dedicated instance of Secrets Manager, built on open source HashiCorp Vault.
Note: if you are a current user of IBM Certificate Manager (service being deprecated), you can use this tool to migrate certificates and their private keys from IBM Cloud Certificate Manager to IBM Cloud Secrets Manager.
With IBM Cloud Secrets Manager, you can connect to a DNS provider by adding a configuration to your instance. By adding a DNS configuration, you can specify the DNS service to use for domain validation when you order certificates through Secrets Manager.
There are two supported DNS providers:
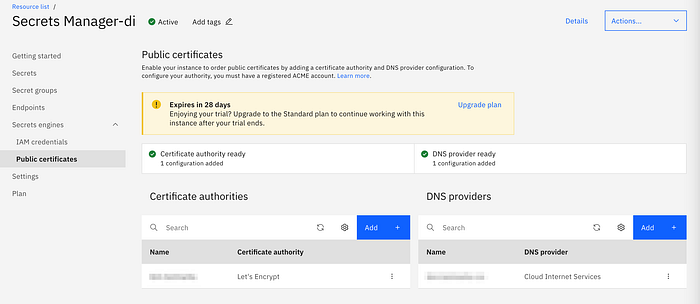
I picked the first one. Before adding a configuration for Cloud Internet Services (CIS), ensure to:
Once done, add a DNS provider (CIS in our case) via the Secrets Manager configuration user-interface, and a Certificate Authority (CA) — Let’s Encrypt — using the acme-account-creation-tool advertised earlier in this post.
Next Steps
- Store all of our secrets in IBM Secrets Manager and expose them to our cluster (EDIT: done, and documented here)
- Explore the concept of sidecar and setup an Nginx sidecar in our pod in order to expose our non-SSL application to the Slack App API. Configure Nginx using ConfigMap and Secret (for the SSL certificate)
- Setup Gunicorn to make our Python application scale better in production
- Work on improvements of the environment setup, and modular deployments, including local builds
Stay tuned!
Conclusion and Acknowledgements
Dear reader, thank you for taking the time to read up to this point. I hope you found the content valuable, and if you have any questions, feedback, success stories, or suggestions for improvements, do not hesitate to reach out.
Last but not least, I’d like to thank my esteemed colleague Criveti Mihai for pushing me to explore new paths (aka Pandora Box), and coping with my almost daily frustration as I was progressing through this journey. Thanks Mihai, and see you on the next “It’s an exam topic” project.
